Hello and welcome to thoughtwisps! This is a personal collection of notes and thoughts on software engineering, machine
learning and the technology industry and community. For my professional website, please see
race-conditions.
Thank you for visiting!
20 Aug 2017
Thank you very much to all organizers (Jimena, Eggya, Florin) and teachers (Steve and Brian) of the Women Who Go London Go workshop yesterday! I learned a lot and have a lot of material for exploring Go further!
If you read some Go code, you will soon notice the presence of two quirky characters: the asterisk (*) and the ampersand(&). For a code gardener coming from the lands of Python, these two creatures can be strange to work with at first (I can only speak for myself, here! ). In the notes below, I will attempt to clarify my current understanding of these two features and how they are used in the Go programming language. If you find mistakes, please do email me at info[at]winterflower.net - always happy to hear corrections and comments!
The asterisk
Variables (in programming) are often used to assign names to pieces of data that our programs need to manipulate. Sometimes, however, we may not want to pass around the whole chunk of data (say for example a large dictionary or list), but instead want to simply say: “This is the location of this piece of data in memory. If you need to manipulate or read some data from it, use this memory address to get it”. This memory address is what we store in variables called pointers. They are declared and manipulated using a special asterisk syntax.
Let’s look at an example.
//package declarations and import omitted
func main(){
helloWorld := "helloworld"
var pointerToHelloWorld *string
...
In the code snippet above, we initialise the variable helloWorld to hold the string “helloworld”. Then we create another variable, which will hold a pointer to the value of the variable helloWorld. When we declare a variable that holds a pointer, we also need to specify the type of the object the pointer points to (in this case, a string).
The ampersand
But how do we go from the variable helloWorld to getting the memory address that we can store in the variable pointerToHelloWorld? We use the & operator. The & is a bit like a function that returns the memory address of its operand(the thing that directly follows it in our code). To continue with the example above, we can get the memory address of helloWorld like this
func main(){
helloWorld := "helloworld"
var pointerToHelloWorld *string
pointerToHelloWorld = &helloWorld
fmt.Println("Pointer to helloWorld")
fmt.Println(pointerToHelloWorld)
//prints out a memory address
}
When we execute this line of code, the value of pointerToHelloWorld is indeed a memory address.
The asterisk again
What if we only have a memory address, but we need to actually access the underlying data? We use the asterisk notation to dereference the pointer (or get the actual object that is at the memory address).
//some code omitted
fmt.Println(*pointerToHelloWorld)
Calling Println on *pointerToHelloWorld will print out “helloworld” instead of the memory address.
Now let’s try to break things a little bit (maybe)
You can apply the ampersand operator on a pointer and you will get another memory address.
func main(){
helloWorld := "helloworld"
var pointerToHelloWorld *string
pointerToHelloWorld = &helloWorld
fmt.Println("PointerToPointer")
fmt.Println(&pointerToHelloWorld)
}
But you cannot call the ampersand operator twice
func main(){
helloWorld := "helloworld"
var pointerToHelloWorld *string
var pointerToPointer **string
pointerToPointer = &&helloWorld)
fmt.Println(pointerToPointer)
}
The compiler will throw an error: syntax error: unexpected &&, expecting expression.
Something slightly different happens if you put parentheses around the first call to &helloworld.
func main(){
helloWorld := "helloworld"
var pointerToHelloWorld *string
var pointerToPointer **string
pointerToPointer = &(&helloWorld)
fmt.Println(pointerToPointer)
}
The compiler will throw an error: cannot take the address of &helloWorld
The journey continues!
17 Aug 2017
Fellow software engineers/hackers/devs/code gardeners, do you keep a notebook (digital or plain dead-tree version) to record things you learn?
Since my days assembling glassware and synthesizing various chemicals in the organic chemistry lab, I’ve found keeping notes to be an indispensable tool at getting better and remembering important lessons learned. One of my professors recommended writing down, after every lab sessions, what had been accomplished and what needed to be done next time. When lab sessions are few and far apart (weekly instead of daily), it is easy to forget the details (for example, the mistakes that were made during weighing of chemicals ). A good quick summary helps with this!
When I first started working for a software company, I was overwhelmed. Academic software development was indeed very different to large scale distributed software development. For example, the academic software I wrote was rarely version controlled and had few tests. I had never heard of a ‘build’ or DEV/QA/PROD environments, not to mention things like Gradle or Jenkins. The academic software I worked on was distributed in zip files and usually edited by only one person (usually the original author). The systems I started working on were simultaneously developed by tens of developers across the globe.
To deal with the newbie developer info-flood, I went back to the concept of a ‘software engineering lab notebook’. At first, I jotted down commands needed to setup proper compilation flags for the dev environment and how to run the build locally to debug errors. A bit later, I started jotting down diagrams of the internals of the systems I was working on and summaries of code snippets that I had found particularly thorny to understand. Sometimes these notes proved indispensable in under-stress debug scenarios when I needed to quickly revisit what was happening in a particular area of the codebase without the luxury of a long debug.
In addition to keeping a record of things that can make your development and debug life easier, a software engineering lab notebook can serve as a good way to learn from previous mistakes. When I revisit some of the code I wrote a year ago or even a few months ago, I often cringe. It’s the same feeling as when you read a draft of a hastily written essay or work of fiction and then approach it again with fresh eyes. All of the great ideas suddenly seem - well- less than great. For example, recently I was looking at a server side process that I wrote to perform computations on a stream of events (coming via ZeroMQ connection from another server ) and saw that for some reason I had included a logging functionality that looped through every single item in an update (potentially 100s ) and wrote a log statement with the data! Had the rate of events been higher, this could have caused some performance issues, though the exact quantification of the impact still remains an area where I need to improve. Things such as these go into the notebook to the ‘avoid-in-the-future-list’.
14 Aug 2017
Introduction
If you regularly browse machine learning websites, you may have seen the image of a self-driving car baffled by a circle of salt drawn on the ground. This ‘hack’ on the car’s sensing devices shows that there is still some work to do to make sure that machine learning algorithms are robust to malicious (or accidental) data manipulation.
Sarah Jamie Lewis’ post on adversarial machine learning is a great introduction and bibliography on the topic of machine learning. One of the papers the article links to is ‘Can Machine Learning be Secure?’ by Barreno et al.
Barreno et al describe various ways to detect attacks and among them talk about examining points near the decision boundary. A large cluster of points around the boundary might indicate that an exploratory attack is taking place.
I wanted to take this idea of points at the decision bounary and explore how one could force a Linear Support Vector Machine classifier trained on the famous Iris dataset to misclassify a rogue point.
Attack description
This attack with premises that make it largely unrealistic. For example, the attacker in this case has full knowledge of the dataset, can visualise the decision boundary and can force the classifier to retrain at will. This most likely will never happen in the real world.
This is a blackbox attack, meaning we assume that the attacker does not know anything about the internals of the Linear SVM classifier and its training process.
- Begin with a classifier trained on the Iris dataset to distinguish between the Iris setosa and Iris versicolor species
- The attacking class will be Iris versicolor. We will inject a rogue point into the Iris setosa dataset and then poison the training data until this rogue point is classified as Iris versicolor.
Prepare the training data
import sklearn
import pandas as pd
import matplotlib
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.head()
|
0 |
1 |
2 |
3 |
4 |
| 0 |
5.1 |
3.5 |
1.4 |
0.2 |
Iris-setosa |
| 1 |
4.9 |
3.0 |
1.4 |
0.2 |
Iris-setosa |
| 2 |
4.7 |
3.2 |
1.3 |
0.2 |
Iris-setosa |
| 3 |
4.6 |
3.1 |
1.5 |
0.2 |
Iris-setosa |
| 4 |
5.0 |
3.6 |
1.4 |
0.2 |
Iris-setosa |
#prepare the class labels. Iris setosa will be labelled as -1, Iris versicolor as 1
X = df.iloc[0:100, 4].values
y= np.where(X=="Iris-setosa", -1, 1)
#prepare the training data
data = df.iloc[0:100, [0,2]].values
Visualise training data
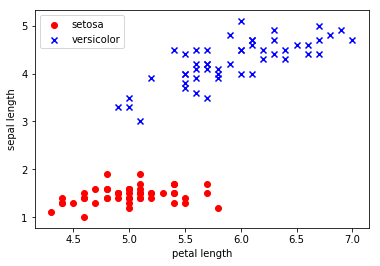
As we can see from the image below, the data points (whose locations are based on the petal length and sepal length of the two species of Iris ) are linearly separable - so we should be able to learn a good decision boundary with the Linear SVM.
plt.scatter(data[:50, 0], data[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(data[50:100, 0], data[50:100, 1], color='blue', marker='x', label='versicolor')
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.legend(loc='upper left')
plt.show()
To monitor the progress of the attack, we will define a helper function below. The function plots the decision boundary learned from the classifier as well as the data. I implemented the function based on the exposition in Python: Deeper Insights into Machine Learning by John Hearty, David Julian and Sebastian Raschka.
def plot_decision_regions(data, y, classifier, resolution=0.02):
"""
A function that plots decision regions based on "Implementing a perceptron algorithm in Python by Raschka et al.
"""
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#meshgrid
x1min, x1max = data[:,0].min()-1, data[:, 0].max()+1
x2min, x2max = data[:,1].min()-1, data[:,1].max()+1
xx1, xx2 = np.meshgrid(np.arange(x1min, x1max, resolution), np.arange(x2min, x2max, resolution))
Z = clf.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=data[y==cl,0], y=data[y==cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
plt.scatter(x=[6.0], y=[1.8],
alpha=0.8, marker='v', c='cyan')
Linear SVM classification
We will be using the Linear SVM implementation from scikit-learn.
from sklearn import svm
clf = svm.LinearSVC()
clf.fit(data, y)
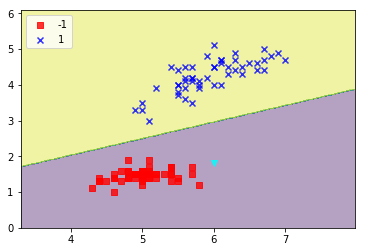
Plotting the decision surface before the attack
This is the situation before we begin poisoning the decision boundary. I have added the rogue point in light blue/cyan into the red class at (6.0, 1.8). The aim will be to move the decision boundary so that this point will be misclassified as blue class.
plot_decision_regions(data, y, clf)
plt.legend(loc='upper left')
plt.show()
Let’s define a few helper functions: add_attack_point will merge new poisoned training data with the existing training dataset, retrain_and_plot will rerun the classifier and plot the resulting decision boundaries.
def add_attack_point(data, y, attack_points, attack_class=1):
"""
Add a new attack point to the dataset
Returns:
--------
New dataset including attack point
New class label vector including label for attacking class (1 in this case)
"""
return np.concatenate((data, attack_points)), np.concatenate((y, np.array(len(attack_points)*[attack_class])))
def retrain_and_plot(clf, new_data, new_y):
"""
Retrain the classifier with new data and plot the result
"""
clf.fit(new_data, new_y)
plot_decision_regions(new_data, new_y, clf)
plt.legend(loc='upper left')
plt.show()
Attack 1 : Add single data point and see what happens
new_data, new_labels = add_attack_point(data, y, [[6.0, 2.0]])
retrain_and_plot(clf, new_data, new_labels)
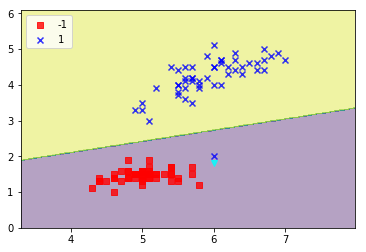
One of the instances from blue class now falls within the decision boundary of the red class, but this has not caused a remarkable shift in the position of the decision boundary. Let’s continue adding more points close to the rogue point we wish to re-classify as blue.
Attack 2: More poisoned datapoints
x1_new = [6.0, 6.1, 6.05, 6.08, 6.09]
x2_new = [1.5, 1.4, 1.55, 1.8, 1.75]
new_vals = map(list, zip(x1_new, x2_new))
new_data_2, new_labels_2 = add_attack_point(new_data, new_labels, new_vals)
retrain_and_plot(clf, new_data_2, new_labels_2)
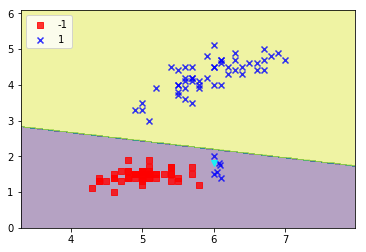
The decision boundary is clearly shifting - close to the mass of new blue attack points.
Attack 3
x1_new = [5.5, 5.6, 5.559, 5.7, 5.45, 6.0, 6.1, 6.2, 5.9]
x2_new = [2.1, 2.105, 2.110, 2.089, 2.0, 1.8, 1.9, 2.0, 1.9]
new_vals = map(list, zip(x1_new, x2_new))
new_data_3, new_labels_3 = add_attack_point(new_data_2, new_labels_2, new_vals)
retrain_and_plot(clf, new_data_3, new_labels_3)
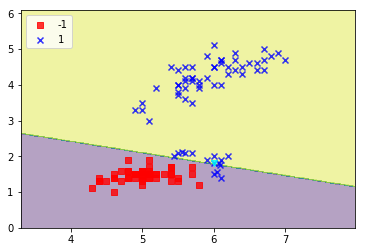
The rogue point is now classified as class 1.
rogue_point = [[6.0, 1.8]]
clf.predict(rogue_point)
Summary
This was a brief and very incomplete experiment with changing the decision boundaries of Linear SVM classifiers by adding poisoned training data close to the decision boundary. One of the major shortcomings of this exposition is that the points were added in a largely random manner around the rogue point without any sort of attack system. In the next few essays on this subject I hope to present a white box approach to poisoning SVMs ( attacks where attacker has intricate knowledge of how support vector machines work ) as well as developing systematic data poisoning approaches.
10 Aug 2017
This post is a set of notes from Jess Frazelle’s talk ‘Benefits of isolation provided by containers’ delivered at O’Reilly Security 2016 Conference in New York. Notes are abbreviated in some places and in places where I was not familiar with concepts from the talk, I’ve added some of my own clarifications/definitions. All mistakes are mine.
How do containers help security?
-
they do not prevent application compromise, but can limit the damage
-
the world an attacker sees inside a container is very different than if she would be looking at an app running without a container
What is a container?
- a group of Linux namespaces and control groups applied to a process
What are control groups (cgroups) ?
Cgroups limit what a process can use. There various kinds of cgroups: for example, the memory cgroup limits what physical or kernel memory. Another example, the blkio group limits various I/O operations.
cgroups are controlled by files
What are namespaces ?
Namespaces limit what a process can see.
They are files located in /proc/{pid}/ns
Docker and defaults
-
by default Docker blocks writing to /proc/{num} and /proc{sys}, mounting and writing to sys
-
LSM (Linux Security Modules ) - a framework that allows the Linux kernel to support a variety of security modules such as AppArmor, SELinux. Docker supports LSMs.
-
people generally don’t want to write custom AppArmor custom profiles, syntax is not great (note to self: look up how to write AppArmor profiles )
Docker and seccomp
-
seccomp is a Linux kernel security module
-
Docker has a default whitelist, which prevents for example cloning a user namespace inside a Docker container
( note to self: look up why this is a weak spot for Linux kernel vulns )
Docker security in the future
- one sad thing: containers need to run as root
-
why: to write to sys/fs for cgroups, we need to be root
-
cgroups cannot be created without CAP_SYS_ADMIN
-
cgroups namespaces: a potential solution to having to be root when creating a cgroup, but turns out this concept just limits what cgroups you can see
- there are patches in the kernel to make it possible to create cgroups with other users, but not yet
09 Aug 2017
Trying not to fall into a rabbit hole is harder than it should be.
Neurons, cut off from the constant stream of novel fast-food information, are struggling to adjust to a life outside of the internet noosphere.
But the brain is a pliable creature. Slowly, it rewires itself to assign neurons performing information grazing to other tasks, one new connection at a time. It does not feel pleasant and the desire to connect back to the buzz of thousands of internet voices is always present.
The info-FOMO (the fear that the biggest and most important thing will happen on the interwebs while you’re away) is always there, but I can learn to live with it until it fades. Also, I won’t be able to lookup Game of Thrones spoilers, so someone will have to tell me what ultimately happens between Daenerys and Jon Snow.
I have not pulled a complete Aziz Ansari ( the GQ Fall 2017 interview with the comedian reports that he has completed disconnected and removed his browsers from his laptop and phone) yet, but I’ve updated /etc/hosts to have even more entries and am considering permanently switching to lynx. It’s a text based browser and thus hopefully will encourage swift and focused information lookups instead of mindless surfing.